Wikipedia:Wikipedia Signpost/Single/2024-08-14

Portland pol profile paid for from public purse
Portland politician spends $6,400 in taxpayer dollars to "spruce up his profile on Wikipedia"
The Oregonian reported that Portland city commissioner Rene Gonzalez spent $6,400 of city taxpayer dollars "to spruce up his profile on Wikipedia" as part of his mayoral bid, by hiring a contractor, WhiteHatWiki, who "helped craft eight requested edits" which were then posted on the article's talk page by a staffer. Only half of these were approved by the volunteer editor who reviewed the request, with one of the rejected ones asking for the removal of a mention that "Gonzalez tagged a member of the right-wing group Patriot Prayer in a Twitter post thanking supporters after his race for City Council in 2022."
In contrast, the newspaper reports that neither Portland's current mayor nor any of Gonzalez' colleagues on the Portland City Council "have paid money to spruce up their Wikipedia entries, according to their offices." It also quotes a political consultant calling the practice "highly unusual" ("I haven’t seen that before"). However, Gonzalez’s chief of staff offered what The Oregonian called "a full-throated defense" of the practice, arguing for a need to be "innovative in how we manage our public profile and how we invest in educating our staff."
Unfortunately this is only one of many such incidents recorded at Conflict-of-interest editing on Wikipedia. – B, HaeB
AI claim might cause a storm
R&D World says you can "write a Wikipedia-style article draft in a few minutes for less than a penny using STORM". STORM stands for 'Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking', and is described as "an open-source artificial intelligence system that promises to generate Wikipedia-style articles on pretty much any topic using large language models and web search."
The R&D World author tested this promise, using the topic of "double descent." Did it work? On the plus side, STORM quickly produced a Wikipedia-like article at a cost of about half a cent. To this non-expert on the topic, it appears to be at least OK. On the negative side, STORM had the advantage that Wikipedia already had an article on double descent, which STORM used to create a new article. For its next trick, I suggest R&D World try to create an article about Bronx cheer.
Fortunately, STORM was written by a team from Stanford University, not from R&D World. See further coverage in this issue's Recent research. – S
Faster, higher, stronger and older

Stephen Harrison in Slate covers the oldest living Olympians, while noting that they are no longer automatically considered to be notable and deserving of an English Wikipedia article unless they've won a medal. His source material is from Paul Tchir, a San Diego State University sports historian, which can be viewed here.
Next time, check Wikipedia first

The New York Times reports on Earl M. Washington, a convicted art forger who is now serving a 52-month term in Federal prison. Washington sold woodblock prints and the intricately carved woodblocks themselves, "more than 3,000 blocks and more than a million prints," sometimes claiming they were antiques dating back to the 16th–17th centuries. After a 2004 Forbes magazine questioned the authenticity of the prints and reported accusations of Washington copying M.C. Escher prints, Washington took a break from the scam until about 2010.
Dr. Douglas Arbittier, who owns a private museum of antique medical instruments, bought 130 prints from Washington from 2013 to 2016 for about $118,810, according to these articles. Washington and Arbittier then lost contact for a few years. Arbittier began to suspect that the works were forgeries. Around 2018, he began a Javert-like pursuit of information about Washington and his forgeries.
In 2020, Arbittier read the Wikipedia article about Washington, which at the time looked like this. "The world comes crashing down at that point," he told the Times. "It was gut wrenching because, oh my God, why did I spend all that money, but also it was a betrayal of the trust and relationship that we had."
Soon he sent a 286-page report to the FBI. Washington was indicted in January 2023, later reaching a plea deal and confessing to reduced charges last summer. He was then sentenced in April 2024.
The Wikipedia article's history, as checked by this reporter, is quite surprising. It was created in 2006, based on the 2004 Forbes story. It has remained quite critical of Washington since then and readers would have seen that Washington's honesty had been questioned. About 2008, the article explicitly included accusations that Washington had forged M.C. Escher prints. Two deletion discussions (in 2006 and 2008, respectively) made clear that Washington might be a scammer... but was he a notable scammer? Washington was accused several times in edit comments and on the talk page of editing or whitewashing the article himself. There were several clumsy attempts to remove negative details in the article, but none of them approached a complete whitewashing. – S
Conservative Jewish media criticize Wikipedia and Wikimedia

Three center-right Jewish media outlets have criticized the English Wikipedia's coverage of the Israel–Hamas war as being biased against Israel.
The Jewish News Syndicate (JNS) says, "Wikipedia hates Israel and Jews":
The JNS article goes on to portray Wikipedia and Wikimedia as "big tech's antisemitic propaganda arm":
The article concludes by calling on Big Tech to rein Wikipedia in.

Another article, in Tablet magazine, comments on the English Wikipedia community's recent decision to designate the Anti-Defamation League "generally unreliable" on matters pertaining to the Israel-Palestinian conflict. The Tablet writer expresses the view that –
The article also reviews the Grabowski/Klein paper (see previous Signpost coverage: 1, 2) and likens the present situation in the English Wikipedia to the historic right-wing takeover of the Croatian Wikipedia, describing it as "incomprehensible" that the Wikimedia Foundation took so long to address that situation.

In a third article, the Jewish Journal gave a very detailed description of the move discussion for the article Allegations of genocide in the 2023 Israeli attack on Gaza, which resulted in that article being renamed Gaza genocide. The Journal notes that the article Allegations of genocide in the 2023 Hamas-led attack on Israel continues to feature the word "allegations" in its title and wonders if this indicates a double standard, pointing out that a discussion to remove the word from that article's title as well appears to have stalled.
The Journal quotes two Wikipedians arguing that there is such a double standard and a third arguing that it may not necessarily be a double standard "if the academic sources don't refer to the Oct. 7 massacre as a genocide but do refer to Israel's actions in Gaza as such." The article ends with a discussion of what Middle East scholar Asaf Romirowsky views as the "Palestinization of the Academy", which he says has led to a problematic focus on Diversity, Equity and Inclusion (DEI) narratives where Palestinians are portrayed as victims worthy of support rather than as perpetrators of crimes. The Journal quotes a Wikipedian who told the publication:
Another quoted in the article sees the greatest problem with Wikipedia in its being "based on academic and journalistic sources, and neither of them are particularly good"; the solution, in their view, is changing the sources Wikipedia is working from. – AK
"Darkness reigns over Wikipedia", finally
Ars Technica reports on the Wikimedia Foundation's recent rollout of dark mode for Wikipedia readers on desktop and mobile, evidently having some gloomy fun while crafting the headline ("Darkness reigns over Wikipedia as official dark mode comes to pass"). Ars points out that Wikipedia is a bit late to the dark mode trend, which "had something of a peak moment around 2019–2020." However, it notes that implementation of this feature is much more difficult than may seem on first glance, quoting from a detailed explanation by Redditor (and Wikipedian) Gwern: "It's truly one of those things where you can get 95% of the way by simply adding 1 line of CSS like body{filter: invert(100%);}, but then to get to 99% correctness and squash all the annoying bugs, you have to completely rewrite your entire site design, and getting to 100% is impossible." See also the Wikimedia Foundation's summary of the process from late 2023. —H
- Editor's note: Signpost stylesheets are part of that final one percent, if anyone wants to help out! —J
In brief

- Internet in a box: Boing Boing says to go buy Wikipedia in a box (see also Internet-in-a-Box) from WMF's store. The price is $58, but as of August 2 they are sold out, though the elves are working overtime to get them back in stock.
- Borderline: The Washington Examiner notes that there have been edit wars over whether U.S. Vice President Kamala Harris should or should not be included in the List of U.S. executive branch czars, based on past descriptions of her – especially by Republicans – as a "border czar" or "immigration czar". (Status at the time of writing is that Harris is not so listed in the article.)
- Unexpected Source of Motivation: Reuters reports that Olympic gymnast Max Whitlock used Wikipedia for motivation after a mental health crisis following the 2020 Tokyo Olympics. He used the site to confirm that he could break a record at the 2024 Olympics by winning a medal in pommel horse. Unfortunately, he had two fourth place finishes.
- Unprintable: The Daily Mail, Sky News, and the Daily Mail again report that a television presenter's Wikipedia article was vandalized for a sum total of 31 minutes. The revision's been revdeled as libelous, but the reversion summary "you would need evidence that he is best known for this" gives a general idea of what it was.
- Edit-a-thon in Canberra: The Canberra Times reports on an editathon held by Franklin Women at Canberra's Shine Dome.
- How the Regime Captured Wikipedia : Pirate Wires avers that the Wikimedia Foundation has transformed Wikipedia into a "hyper-centralized space of top-down social justice activism and advocacy", and weighs in with gusto on the Framgate incident of 2019.
—J
STORM: AI agents role-play as "Wikipedia editors" and "experts" to create Wikipedia-like articles, a more sophisticated effort than previous auto-generation systems
A monthly overview of recent academic research about Wikipedia and other Wikimedia projects, also published as the Wikimedia Research Newsletter.
STORM: AI agents role-play as "Wikipedia editors" and "experts" to create Wikipedia-like articles
A paper presented in June at the NAACL 2024 conference describes "how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages." A "research prototype" version of the resulting "STORM" system is available online and has already attracted thousands of users. This is the most advanced system for automatically creating Wikipedia-like articles that has been published to date.
The authors hail from Monica S. Lam's group at Stanford, which has also published several other papers involving LLMs and Wikimedia projects since 2023 (see our previous coverage: WikiChat, "the first few-shot LLM-based chatbot that almost never hallucinates" – a paper that received the Wikimedia Foundation's "Research Award of the Year" some weeks ago).
A more sophisticated effort than previous auto-generation efforts
Research into automated generation of Wikipedia-like text long predates the current AI boom fueled by the 2022 release of ChatGPT. However, the authors point out that such efforts have "generally focused on evaluating the generation of shorter snippets (e.g., one paragraph), within a narrower scope (e.g., a specific domain or two), or when an explicit outline or reference documents are supplied." (See below for some other recent publications that took such a more limited approach. For coverage of an antediluvian historical example, see a 2015 review in this newsletter: "Bot detects theatre play scripts on the web and writes Wikipedia articles about them". The STORM paper cites an even earlier predecessor from 2009, a paper titled "Automatically generating Wikipedia articles: A structure-aware approach", which resulted in this edit.)
The STORM authors tackle the more general problem of writing of a Wikipedia-like article about an arbitrary topic "from scratch". Using a novel approach, they break this down it into various tasks and sub-tasks, which are carried out by different LLM agents:
The use of external references is motivated by the (by now well-established) observation that relying on the "parametric knowledge" contained in the LLM itself "is limited by a lack of details and hallucinations [...], particularly in addressing long-tail topics". ChatGPT and other state-of-the art AI chatbots struggle with requests to create a Wikipedia article. (As Wikipedians have found in various experiments – see also the Signpost's November 2022 coverage of attempts to write Wikipediesque articles using LLMs – this may result e.g. in articles that look good superficially but contain lots of factually wrong statements supported by hallucinated citations, i.e. references to web pages or other publications that do not exist.) The authors note that "current strategies [to address such shortcomings of LLMs in general] often involve retrieval-augmented generation (RAG), which circles back to the problem of researching the topic in the pre-writing stage, as much information cannot be surfaced through simple topic searches." They cite existing "human learning theories" about the importance of "asking effective questions". This task in turn is likewise challenging for LLMs ("we find that they typically produce basic 'What', 'When', and 'Where' questions [...] which often only address surface-level facts about the topic".) This motivates the authors' more elaborated design:
Role-playing different article-writing perspectives
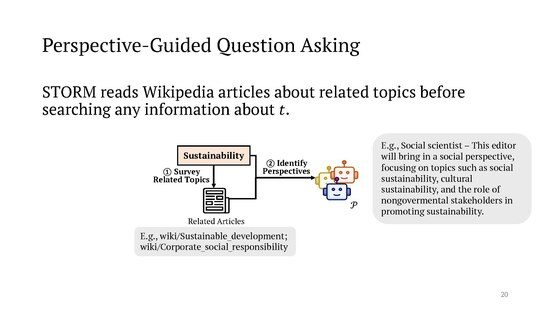
In more detail, after being given a topic to write about, STORM first "prompts an LLM to generate a list of related topics and subsequently extracts the tables of contents from their corresponding Wikipedia articles, if such articles can be obtained through Wikipedia API". In an example presented by the authors, for the given topic sustainability of Large Language Models, this might lead to the existing articles sustainable development and corporate social responsibility. The section headings of those related articles are then passed to an LLM with the request to generate a set of "perspectives", with the prompt
In the authors' example, one of the resulting perspectives is a "Social scientist – This editor will bring in a social perspective, focusing on topics such as social sustainability, cultural sustainability, and the role of nongovermental [sic] stakeholders in promoting sustainability."
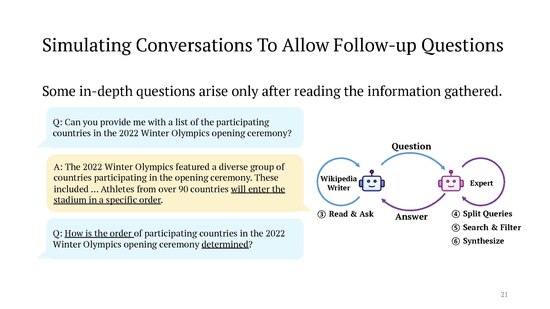
Each of these "Wikipedia editors" then sets out to interview a "topic expert" in their field of interest, i.e. the system simulates a conversation between two LLM agents prompted to act in these roles. The "expert" is instructed to answer the "Wikipedia editor"'s questions by coming up with suitable search engine queries and looking through the results. From the various prompts involved:
The online version of the STORM tool allows one to watch these behind-the-scenes agent conversations while the article is being generated, which can be quite amusing. (The "Wikipedia editor" is admonished in the prompt to politely express its gratitude to the "expert" and not to waste their time with repetitive questions: "When you have no more question to ask , say " Thank you so much for your help !" to end the conversation . Please only ask one question at a time and don 't ask what you have asked before .") The authors are currently working on a follow-up project called "Co-STORM" where the (human) user can become part of these multi-round agent conversation, e.g. to mitigate some remaining issues like content that is repetitive or conflicts between the different "experts".
(Like the aforementioned use of externally retrieved information, such agent-based systems have become quite popular in LLM-based AI over the last year or so. The authors use DSPy – a framework likewise developed at Stanford – for their implementation. Another well-known framework is LangChain, who actually released their own implementation of STORM as a demo of their "Langgraph" library back in February, based on the description and prompts in a preprint version of the paper, and shortly before the paper's authors published their own code.)
The paper states that the results of the "experts'" search engine queries "will be evaluated using a rule-based filter according to the Wikipedia guideline [ Wikipedia:Reliable sources ] to exclude untrustworthy sources" before the "experts" use them to generate their answers. (In the published source code, this is implemented in a somewhat simplistic way, by excluding those sources that Wikipedians have explicitly marked as "generally unreliable", "deprecated" or "blacklisted" at Wikipedia:Reliable sources/Perennial sources. But of course, search engine results contain many other sources on the internet that don't match the WP:RS requirements, either. In this reviewer's experiments with the STORM system, that turned out to be a significant limitation, at least if one were to use the output as basis for creating an actual Wikipedia article. One idea might be to restrict search to a search engine such as Google Scholar. But academic journal paywalls represent a challenge to this idea, according to a conversation with one of the authors.)
Putting the article together
Having gathered material from those agent conversations, STORM proceeds to generating an outline for the article. First, the system prompts the LLM to draft the outline only based on its internal (parametric) knowledge, which "typically provides a general but organized framework." This is then refined based on the results of the perspective-based conversations.
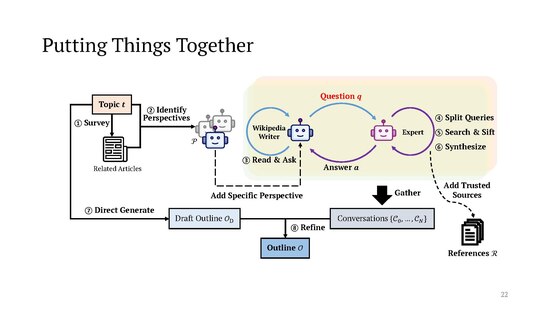
Lastly, the system composes the full article section by section, using the outline and the set of all reference documents R collected by the "topic experts". Another complication here is that "since it is usually impossible to fit the entire R within the context window of the LLM, we use the section title and headings of its all-level subsections to retrieve relevant documents from R based on semantic similarity". The LLM is then prompted separately for each section to generate its text using the references selected for that section. The sections are then concatenated into a single document, which is passed once more to the LLM with a prompt asking it to remove duplications between the sections. Finally, the LLM is called one last time to generate a summary for the lead section.
All this internal chattiness and repeated prompting of the LLM for multiple tasks comes at a price. It typically costs about 84 cent in market price API fees to generate one article (when using OpenAi's top-tier model GPT 4.0 as the LLM, and including the cost of search engine queries), according to an estimate shared by one of the authors last month. However, the freely available research prototype of STORM is supported by free Microsoft Azure credits. (This reviewer incurred roughly comparable costs when trying out the aforementioned LangChain implementation, also using GPT 4.0.) On the other hand, a reviewer at the website "R&D World" (see coverage in this issue's "In the Media") reported getting "A draft article in minutes for $0.005" while running the STORM code on Google Colab (albeit possibly by relying on initial free credits from OpenAI too).
Evaluating article quality
So are all these extra steps worth it, compared to simpler efforts (like asking ChatGPT "Write a Wikipedia article about...")?
First, to enable automated evaluation, the authors "curate FreshWiki, a dataset of recent high-quality Wikipedia articles, and formulate outline assessments to evaluate the pre-writing stage." The FreshWiki articles are used as ground truth, to "compute the entity recall in the article level" (very roughly, counting how many terms from the human-written reference article also occur in the auto-generated article about the topic) and the similar ROUGE-1 and ROUGE-L metrics (which measure the overlap with the reference text on the level of single words and word sequences).
The author compare their system to "three LLM-based baselines", e.g. "Direct Gen, a baseline that directly prompts the LLM to generate an outline, which is then used to generate the full-length article." They find that STORM indeed comes out ahead on these scores.
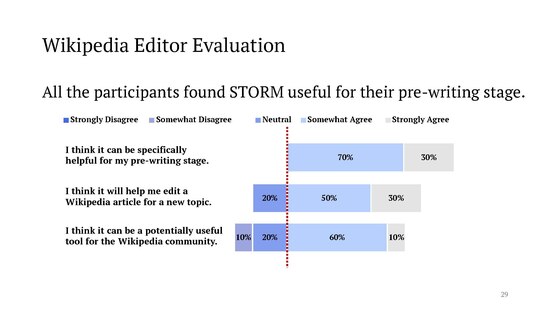
For manual evaluation, the authors invited [1] [2]
Checking citations
Another part of the automated evaluation checks whether the cited passages in the reference document actually support the sentence they are cited for. This problem is known as textual entailment in natural language processing. The authors entrust these checks to a current open-weight LLM (Mistral 7B-Instruct). This choice may be of independent interest to those seeking to use LLMs for automatically checking text-source integrity on Wikipedia.
They find that
As a concrete example of such irrelevant sources, in this reviewer's test with creating an article on the German Press Council (Deutscher Presserat – a long-tail topic where not too many high-quality English-language online sources exist), the otherwise quite solid list of references included several pages about the wrong entity: One about the Luxembourgian press council, another about the unrelated German Ethics Council, and a third one about Germany and the UN Security Council. This seems primarily a failure in the search engine retrieval stage, rather than a LLM hallucination problem per se. But it was also not caught by the "topic experts" despite being prompted to "make sure every sentence is supported by the gathered information".)
Conclusion and outlook
The authors take care to avoid the impression that STORM's outputs can already match actual Wikipedia articles in all respects (only asserting that the generated articles have "comparable breadth and depth to Wikipedia pages"). Their research project page on Meta-wiki is diligently titled "Wikipedia type Articles Generated by LLM (Not for Publication on Wikipedia)". Nevertheless, STORM represents a significant step forward, bringing AI a bit closer to replacing much of the work of Wikipedia article writers.
On July 11, one of the authors presented the project at a Wikipedia meetup in San Francisco, and answered various questions about it (Etherpad notes). Among others aspects already reported above, he shared that STORM had already attracted around 10,000 users (signups) who use it for a variety of different uses cases – not just as a mere Wikipedia replacement. The project has received feature requests from various interested parties, which are being implementing by a small development team (3 people), as visible in the project's open-source code repository.
Other recent publications
Other recent publications that could not be covered in time for this issue include the items listed below. Contributions, whether reviewing or summarizing newly published research, are always welcome.
.png)
"Retrieval-based Full-length Wikipedia Generation for Emergent Events" using ChatGPT and other LLMs
From the abstract:
From the paper:
The authors are a group of ten researchers from Peking University and Huawei. Published just six days after (the first version of) the "STORM" paper by Stanford researchers covered above, neither of the two papers cites the other.
"Surfer100: Generating Surveys From Web Resources, Wikipedia-style"
From the abstract:
"GPT-4 surpasses its predecessors" in writing Wikipedia-style articles about NLP concepts, but still "occasionally exhibited lapses"
From the abstract:
.png)
.png)
"Automatically Generating Hindi Wikipedia Pages using Wikidata as a Knowledge Graph: A Domain-Specific Template Sentences Approach"
From the abstract:
A master's thesis by one of the authors covers the process in more detail.
(Neither the paper nor the thesis mention the Wikimedia Foundation's Abstract Wikipedia project, which is pursuing a somewhat similar approach.)
"Grounded Content Automation: Generation and Verification of Wikipedia in Low-Resource languages."
From the abstract:
See also our earlier coverage of a related paper: "XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages"
"Abstract Wikipedia is a challenge that exceeds previous applications of [natural language generation] by at least two orders of magnitude"
From the abstract:
From the "Conclusion" section:
See also Wikipedia:Wikipedia Signpost/2023-01-01/Technology report for a discussion of some technical challenges surrounding NLG on Abstract Wikipedia, including past debates about adopting Grammatical Framework for it
"Using Wikidata lexemes and items to generate text from abstract representations", with possible use on Abstract Wikipedia/Wikifunctions
From the abstract:
"Censorship of Online Encyclopedias: Implications for NLP Models"
From the abstract:
Briefly
- See the page of the monthly Wikimedia Research Showcase for videos and slides of past presentations.
- A "NLP" for Wikipedia workshop will take place as part of the Empirical Methods in Natural Language Processing on November 16, 2024. The paper submission deadline is August 29.
References
Twitter marks the spot
The acquisition of Twitter by Elon Musk from 14 April to 28 October 2022, and its subsequent rebranding as X on 24 July 2023, have caused extensive debates on Wikipedia. Central to these discussions is whether this constitutes the creation of an entirely new entity, and if so, how this should be reflected in articles. The main article about the social network is currently under the title 'Twitter', but the title of Twitter under Elon Musk raised concerns about Wikipedia's policy on biographies of living persons, as it was argued that it could appear to hold Musk solely accountable for all the controversies (even when he was no longer the CEO).
The X-CEO
 Ex-CEO Elon Musk
Ex-CEO Elon Musk X CEO Linda Yaccarino
X CEO Linda Yaccarino
.jpg)
.jpg)
When Musk announced Linda Yaccarino as his successor as CEO, editors discussed whether to continue covering his influence on the platform in Twitter under Elon Musk, or to restrict it to his tenure as CEO. Concerns were raised by Jtbobwaysf about avoiding content duplication with the main Twitter article and deciding what updates should be included. Horse Eye's Back argued that the purpose of the article was to cover significant developments related to Musk's leadership, as indicated by 'under' in the title.
To gather wider community input, a request for comment (RfC) discussed whether the article on Twitter during Elon Musk's tenure should adhere to the stricter standards of biographies of living persons (BLP), given its focus on Musk. BLP guidelines, which require careful sourcing for content about living individuals, were under debate whether they applied to the entire article, or just the parts mentioning Musk. There was also concern about the potential for content forks, and how to handle overlapping information with the main Twitter article, particularly regarding sensitive allegations and the reliability of sources. The discussion was procedurally closed by Dsprc, noting that BLP policies should apply to the article due to its focus on Musk.
Snowstorm
Early requests to change the title of the main Twitter article were consistently rejected, due to the rebranding being incomplete, and the name remaining widely recognized. These early discussions were quickly closed, via the snowball clause, in order to not exhaust community time. Strong consensus was to retain the article's title until the rebranding was fully realized and adopted. Despite Musk's rebranding efforts, these earlier discussions on this matter closed with a consensus that 'Twitter' was still the more recognizable and used name.
The repeated nature of these proposals — and their consistent failure — led some editors to discuss a move moratorium on future renaming requests pending more definitive evidence of a change in the situation. Some contributors favoured a shorter one of around three months, with some saying six months would be excessive. The consensus leant towards allowing an exception if the official domain actually changed to x.com. The proposed moratorium was seen as a way to balance avoiding constant debate with allowing flexibility to respond to significant changes.
In May 2024, the social network changed its domain to x.com and a move was requested by ElijahPepe to move Twitter to X (social network). The proposal's opponents maintained that 'Twitter' was more recognizable, that it was used more prominently in reliable sources, and that an immediate change could confuse readers and obscure the article. Some suggested a compromise, like splitting the article into sections, or creating separate entries for Twitter and X. The supporters of this move argued that the substantial changes under Musk, including new features and a shift in company culture, warranted a distinct article for X, to avoid confusion and ensure a clear historical separation (similar to other rebranded companies). Some opposition argued that X is essentially the same platform as Twitter, albeit under new management, and that creating separate articles could cause confusion and redundancy. Some argued that the core nature of the social network remains unchanged, making a single, continuous article more suitable. A compromise was suggested by keeping the Twitter article focused on its history up to 2022 while creating a new article for X, aiming to balance historical accuracy with practical readability and editorial consistency. The request was closed as unsuccessful by Sceptre; and thirty-eight minutes later, ElijahPepe requested to move Twitter under Elon Musk to X (social network) and was met with initial support and the same points from the previous discussion were raised.
The article was moved to 'X (social network)' and this decision was defended by the closer, citing personal judgement and perceived majority support. A subsequent move review was opened as it was thought that the move from Twitter under Elon Musk to X (social network) was made prematurely, with 29 supporting and 20 opposing the change not indicating a consensus. This approach was seen to have overlooked the need for a clear, policy-based consensus and relied on a narrow interpretation. They contended that the change, which also suggested a shift in content scope, might cause confusion and was made without fully addressing concerns about whether 'Twitter' and 'X' should be distinct entities. Theleekycauldron later closed the move review and the page was defaulted to its original name with the move discussion being relisted.
As the discussion was re-opened, Masem argued that the changes — including new features, policies, and management changes — justify the creation of distinct articles. This would allow for a clearer distinction between the historical Twitter and the current X. Some opponents viewed Twitter and X as the same platform under different names, warning that such a division might mislead readers into perceiving them as separate entities when X is merely a rebranding of Twitter. Proposed solutions include either maintaining a single article with a section dedicated to the rebranding or creating a new article for X, and Jorahm supported preserving Twitter as a historical article.
In August 2024, a request to move List of most-followed Twitter accounts to 'List of most-followed X accounts' was proposed by MarkJames1989, citing that most reliable sources now refer to the platform as X. This request was met with immediate opposition, with Robertsky arguing that the parent topic remains 'Twitter', and the move will likely be challenged; and SmittenGalaxy noting that the many attempts to rename Twitter-related articles have been unsuccessful.
Determine the number of entities to find 𝕏
.jpg)
A survey was held in November 2023 to decide on whether to split content related to Twitter's history before and after Musk's acquisition, with proposals to reorganize the content to reflect the platform's transformation. Options included merging and moving sections, splitting the history into separate articles, or retaining a unified history. Creating new articles which split the history of Twitter was suggested, and some participants argue that splitting the history section prematurely could disrupt the consensus process and weaken the comprehensiveness of the main Twitter article, which relies on history for context. Others supported the split, asserting that Twitter's history is substantial enough to merit a standalone article. Concerns about content duplication across related pages have been raised, with CommunityNotesContributor suggesting plans on how information should be distributed to avoid redundancy.
A brief discussion took place to determine where the redirect X (social network) should be targeted, and another discussion considered whether the rebranding should influence the introduction of the article as "Twitter, officially known as X since July 2023" or "X commonly referred to by its former name, Twitter". Another RfC debated the most accurate disambiguator to describe Twitter's rebranding as X, with options like 'Rebranded to X', 'Renamed to X', and others being considered. The terms 'rebranded' and 'renamed' had support, with proponents of 'rebranded' arguing it best reflects the platform's continuity under a new name, avoiding implications that Twitter has ceased to exist.
Post-publication developments
The May 2024 request to move Twitter under Elon Musk to 'X (social network)' was closed by Wbm1058, who determined there was no consensus to separate coverage of Twitter and X. In their closing statement, they used the analogy of base ball, noting that although it has evolved over time, it still redirects to its modern version. They later recommended that the next request should be to move Twitter to X (social network), as the AP Stylebook has been updated to prefer 'X' with references to 'Twitter' when necessary; and reliable sources, including The New York Times, are following this style. Two days later, ElijahPepe requested this move.
Another Wikimania has concluded
Wikimania 2024

The Wikimania 2024 conference in Katowice, Poland, had events taking place from 7 August to 10 August. Many programs as well as the opening and closing ceremonies were live-streamed, and can currently be viewed on the WMF YouTube channel. There are also plenty of media available on Wikimedia Commons.
The Sustainable Development Goals continued to be a particular focus of Wikimania through many related sessions. Wikimedians for Sustainable Development is one such group which maintains this interest by recruiting submissions and organizing networking among projects.
Wikimania 2025 was recently announced to be in Nairobi, Kenya. Wikimania 2026 will be held in Paris, France. – S, Bl, AK
Movement Charter feedback published
After the Movement Charter ratification vote last month from the affiliates and individual voters, the Movement Charter Drafting Committee (MCDC) and Charter Election Commission (CEC) published all comments submitted during the vote. This involves 65 comments from Affiliates and 447 individual comments, though no summary of the same is yet available.
After the WMF Board of Trustees (BoT) chose to not ratify the current draft of the Movement Charter, it is not currently clear what the future steps for the Movement Charter are. The charter was previously covered by The Signpost in the issues published on 22 July, 4 July, and 8 June.
One of the three proposals passed by the BoT in lieu of the Movement Charter was the Product and Technology Advisory Council, with members selected by the WMF. This council will comprise 16 members including 8 volunteers, one of whom is guaranteed to be from English Wikipedia. Applications are open till 16 September. – S
Brief notes
- New email address for reporting undisclosed paid/COI editing: To deal with reports of undisclosed conflict-of-interest or paid editing, where reporting such editing on-wiki would lead to posting another editor's personal information without their consent, editors can now send reports to paid-en-wp
 wikipedia.org. These reports are handled using the volunteer response team (VRT) system by members of the CheckUser and Oversight teams, or by specially-appointed administrators. Reports may be sent to the Arbitration Committee for review at their discretion; for example, a credible report involving an administrator should be referred there. For more details see WP:COIVRT.
wikipedia.org. These reports are handled using the volunteer response team (VRT) system by members of the CheckUser and Oversight teams, or by specially-appointed administrators. Reports may be sent to the Arbitration Committee for review at their discretion; for example, a credible report involving an administrator should be referred there. For more details see WP:COIVRT. - Barkeep49 resigns from ArbCom: Last month, Barkeep49 resigned from the Arbitration Committee (ArbCom) to focus all his energy on the U4C. This brings ArbCom to 10 active and 3 inactive members.
- Wikimedia Foundation Bulletin: The WMF published the latest issue of the Wikimedia Foundation bulletin. Of note are a blog post about Dark Mode in Wikipedia, a consultation about WikiProjects across various projects, and a message from WMF CEO Maryana Iskander.
- New user groups: The Affiliations Committee announced the approval of the newest Wikimedia movement affiliates, the Wikimedians of Singapore User Group, the WikiMedistas Wayúu and the Wikimedia Community of Togo User Group.
- Annual reports: Kashmiri Wikimedians User Group, Wikimedia Community User Group Côte d’Ivoire.
- Articles for Improvement: This week's Article for Improvement is Social experiment. Please be bold in helping improve this article! Next week's Article for Improvement (beginning 19 August 2024) is Keygen.
- Admin numbers up slightly: The number of active admins is up slightly from the low point of 430 active admins, 30 June-1 July, to an average of 435.4 for the month of July.
Nano or just nothing: Will nano go nuclear?
.png)
Nano Nuclear Energy is in the business of designing very small nuclear power generators. Though they don’t yet have any operating generators, their intention is to make them small enough to carry around on or tow behind a large truck, or even have them power ships while loaded on the ship’s deck. Technically, reactors of this size might be better described as "microreactors" rather than "nanoreactors". You can see an animation of their vision on YouTube.
According to Hunterbrook Media, a newspaper associated with a short seller named Hunterbrook Capital, NNE has "no revenue, products, or patents for its core technology". But it does have a plan to produce its small nuclear generators starting in 2030-2031, a timeline that an expert asked by Hunterbrook Media called "frankly laughable". Hunterbrook also raises questions about management quality, slow applications for regulatory approvals, and the need to raise "hundreds of millions of dollars for research and development" before the product can go to market.
Similar facts and questions were raised by a story in May from Fast Company without raising the possibility that NNE could become the target of short sellers. NNE stock was listed on NASDAQ with a market capitalization of about $600 million before the Hunterbrook report. This year its auditor has been fined $2 million by the Public Company Accounting Oversight Board (PCAOB) for failure to maintain auditing quality control standards. NNE, to say the least, is an unusual company.
Hunterbrook

How paid editors squeeze you dry
31 January 2024
"Wikipedia and the assault on history"
4 December 2023
The "largest con in corporate history"?
20 February 2023
Truth or consequences? A tough month for truth
31 August 2022
The oligarchs' socks
27 March 2022
Fuzzy-headed government editing
30 January 2022
Denial: climate change, mass killings and pornography
29 November 2021
Paid promotional paragraphs in German parliamentary pages
26 September 2021
Enough time left to vote! IP ban
29 August 2021
Paid editing by a former head of state's business enterprise
25 April 2021
Hunterbrook Media published its story about NNE at 9:45 am Friday, July 19, 2024 and announced that Hunterbrook Capital, technically a hedge fund, had sold short NNE’s stock, betting that the price would fall. NNE’s stock price fell 7.43% before noon, but finished the day up 1.05% at $19.30. As of the publication date of The Signpost (August 14), the price has fairly steadily declined since July 19 to $7.70.
Neither NNE nor Hunterbrook have responded to inquiries from The Signpost made soon after the Hunterbrook report. NNE has responded to the Hunterbrook story by means of a August 13 press release, titled "NANO Nuclear Energy Fights Back Against Short Sellers" which included a letter from their lawyers. Taken together, these documents essentially deny all of Hunterbrook's claims and threaten to sue them for defamation.
It seems that one of these companies must be stretching the truth here. How can we find out which one?
The New Yorker published a 3,300 word article in May about Hunterbrook. They call Hunterbrook Media and Hunterbrook Capital "conjoined twins", though it's clear that Hunterbrook Capital is the owner of the joint business. Because Hunterbrook Capital is registered with the SEC as a hedge fund, Hunterbrook Media cannot use any non-public information in its stories without risking being considered an insider trader. They use only well documented publicly available information in their stories, and publish them openly on their website with no ads or paywall. Hunterbrook Capital has pre-publication access to the material, and can trade, long or short, based on that information.
On the face of it Hunterbrook is an unusual company, but that doesn’t necessarily mean they are trying to fool anybody. I should note that I’ve cited Hindenburg Research, another short seller, in a Signpost article and found their information was reliable. Nevertheless, that doesn't necessarily mean that Hunterbrook's information will be correct. Readers should be aware that short selling, the practice of betting that a stock's price will go down, is a controversial business and that many short sellers have been accused of exaggerating their reports in order to drive the stock price down further.
Paid editing on Wikipedia?
One method of seeing how forthright and transparent businesses are is to check the Wikipedia articles about them. Are the articles peppered with edits from blocked sock puppets or apparent undeclared paid editors? Wikipedia retains almost every edit, so edits to an article by blocked or banned editors are fairly easily-checked. At the same time, no investigation solely using Wikipedia's database can be absolutely certain of an editor's identity. They may be impersonating someone to cause them embarrassment, a practice known as Joe jobbing. Ultimately, we rely on the judgement of administrators and checkusers who officially decide whether to block sock puppets, and on participants at Articles for Deletion, who sometimes decide whether an article has been improperly created.
There’s not much to say about Hunterbrook using this method, since I couldn't find any Wikipedia articles about the company, or its owners or employees.
NNE also is lacking in Wikipedia articles in the usual places. They’ve almost all been deleted. But there is a record of three separate deletion discussions. The first two were for the company, Nano Nuclear Energy (both resulting in deletion). The second nominator said there were "some articles about the broader technology mention the company in passing, but no real coverage of the company itself". A reviewer, noting the lack of independent sources, kindly wrote TOO SOON. There is a surviving article on the Spanish Wikipedia, as well as an archived copy of an English Wikipedia article from May 4, 2024, so readers can judge for themselves whether the company was notable. Using Google Translate, the Spanish article looks nearly identical to the archived English article.
Three socks and a sock farm
The third AfD discussion was about NNE's founder and president Jay Jiang Yu. An AfD reviewer wrote that the article was "paid-editing sock drivel". The closer agreed, with most of the other reviewers finding no reliable sources, thus !voting to delete. Two sock puppets, "EliteBrandRealm" and "Eugenio Montilla" both voted to keep on February 18, 2024 and were both indefinitely blocked the same day. Eugenio Montilla was blocked as a sock of the master Claudio Antonio Ruiz. EliteBrandRealm was investigated as part of the Claudio Antonio Ruiz sockfarm, but ultimately blocked separately. There were about 45 blocked socks operating on several Wikipedia language versions involved in the investigation of the Claudio Antonio Ruiz sockfarm.
At Wikimedia Commons, Leolaria1997 made 15 of their 17 edits on NNE logos, but was not blocked there. They were blocked on the English language Wikipedia for advertising on Wikipedia, including creating the article Nano Nuclear Energy, Inc. (notice the "Inc."), as well as editing the article of a plastic surgeon who specialized in the "Brazilian butt lift".
Claudio Antonio Ruiz also uploaded another NNE logo to Commons and made edits to the article of the same plastic surgeon, but their blocks were not directly linked.
One other connection to NNE was an autobiography submitted in 2015 to Articles for Creation by User:Dr. Carlos O. Maidana. This editor was warned about the autobiography violating Wikipedia rules. All three of his edits have now been deleted. Dr. Carlos O. Maidana is listed as "Head of Thermal Hydraulics and Space Program" by NNE. He has worked at the Idaho National Laboratory in related areas, and it is not clear whether he worked for NNE in 2015. This may just be a case of a person who was unfamiliar with Wikipedia rules making a flawed contribution in good faith.
No evidence has been found about Hunterbrook editing Wikipedia. But the evidence on NNE, gathered mostly in the AfD discussions and sock puppet investigations looks solid for the purposes of Wikipedia. The article named "Nano Nuclear Energy" was deleted twice, for lack of notability. Another article named "Nano Nuclear Energy, Inc." was created by a user blocked for advertising on Wikipedia and the article was quickly deleted. Though blocked separately, this editor had some connections with the undeclared paid editor Claudio Antonio Ruiz, who is listed as the master of a large sock farm.
The article on NNE's founder and president Jay Jiang Yu was edited by undeclared paid editors who were part of the same sock farm. The AfD reviewers and sock puppet investigators should be congratulated for their speed and accuracy. It appears that the paid editing was started late last year and ended by May.
The Signpost makes no representation about who might have made any paid edits, nor about who might have paid for them. We only state that there is some evidence consistent with paid editing on articles related to NNE.
HouseBlaster's RfA debriefing
There is a lot I can say about Wikipedia:Requests for adminship/HouseBlaster. If your time is short or you would (wisely) prefer not to read my ramblings, here is a quick summary:
- My RfA was in fact stressful
- The outcome of an RfA is a lot less certain when it is your RfA
- I was expecting "content creation" opposes, and I agree that my content creation is not the best. Additionally, content creation is hard to measure quantitatively (§ Content creation)
- I was not expecting "bureaucratic" opposes, and will strive to improve in that way (§ On being bureaucratic)
- The Doug diff was one of those "why in the world did I say that?" moments (and it gets its own section)
- Good nominators are essential (and thank you, Moneytrees and theleekycauldron)
- If you take away nothing else: Please do not ask superlative questions!
What I have learned
Content creation
Going into the RfA, I knew I was getting these types of opposes and I was okay with it.
I want to create more content in the future, but it isn't something that I usually find as enjoyable as working at CfD. I also need an article to "speak to me" to avoid getting bored.
That being said, I think that arguments about my percentage or raw number of mainspace edits were more than a little silly. One of my nominators, theleekycauldron, had approximately 6,400 mainspace edits representing 16.3% of her edits. I had approximately 8,400 mainspace edits representing 28% of my edits. In other words, both as a percentage and as a raw number I have more mainspace edits than theleekycauldron. I had written one GA and one additional DYK. She had written many, many more than that. Anyone opposing her RfA for a lack of content creation seriously needs to reexamine what they mean by a "lack of content creation".
Opposing for a lack of content creation is a perfectly reasonable position to take, even if I disagree with it. But content creation is not really something that can be measured quantitatively. (And yes, I regret using authorship percentage as an indicator of my contributions to 1934 German head of state referendum.) Opposing for a lack of GAs or FAs? Reasonable, even though I disagree. But don't oppose people because of mainspace percentage or raw edit numbers because they are at best meaningless and more likely actively misleading. (And the flip side is true, too: A high mainspace percentage or raw number might merely indicate a large amount of AWB use.)
On being bureaucratic
I do tend to do things by the book because that is how I learn how to do things: By reading the book. However, going forward I will be more mindful of this and strive to improve. That is not to say I will become an ignore every single rule person, but I will try to be more flexible.
The Doug Weller diff
I am going to make this short, not to minimize what I said but simply because there is not a whole lot to say that has not already been said. It is one of those comments which I cannot really understand why I thought it was appropriate to say to an internet stranger. It was insensitive—to say the least—and I should not have said it. I was very grateful that the comment was on a "live" talk page: it was something that could be <s>struck</s> and my apology could go inline. In the future, I will be more mindful of the impact of my words.
- To provide additional information, a copyeditor for The Signpost has included Doug Weller's response a few weeks after the RfA closed:
The Creative Lizzie saga
My answer to standard question number three (about conflict/stress) was actually originally going to be paragraph one of two. Here was my draft of paragraph two:
Even though it was initially raised by an oppose voter, I think it actually helped my candidacy. See, for instance, this support.
However, there is another small thing which I want to mention: during the RfA, I got this email from Snowmanonahoe, requesting permission to post the following in response to Lightburst's oppose:
I declined to give permission, for two reasons: I did not like the optics of collusion between a candidate and someone else, and there are people who will oppose you for participating in off-wiki things: I did not want to open that can of worms.
And at the end of the day, Creative Lizzie is happy. I still get occasional emails from her about her newest adventures in life, her pride is not damaged beyond repair, she responded okay to the aforementioned flippant reply, and the Jonathan Baldwin Turner article looks much better than it did before she got involved.
Badgering versus responding to opposes
There is a difference between badgering and responding to opposes. Anything which says "that is actually not a reason to oppose because [reason]" is not helpful. That can go in your own !vote rationale.
On the other hand, providing additional context regarding factual matters raised in the oppose can be helpful. I am glad that people brought up the context to the
bitey replyin response to the oppose left by Lightburst (see § The Creative Lizzie saga for more).
Talking to theleekycauldron, she put it better than I could: "questions of fact should be discussed in the oppose section, but not questions of values". There is obviously a gray zone between the two, and I would err on the side of caution and not responding. But the sentiment is absolutely correct.
The "rule" against candidates replying to !votes
We had a tradition in which candidates do not respond to opposes, but it is being reexamined. Currently, responding to opposes does not in itself immediately trigger further opposes (though the content of what you say might). However, there is no expectation that the candidate does so, and not responding to an allegation is not seen as tacit endorsement of it. I think that this is the right balance, and hope we do not move away from it. There are many things wrong with RfA, but our current culture surrounding candidates responding to !votes is not one of them.
Thoughts on further RfA reform
The single best investment I have made in my life was sinking however many hours it took to get RfC: should RfAs be put on hold automatically? over the finish line. It helped, and it helped a lot. Seriously. The 67 minutes between the scheduled closing and when Acalamari put the bow on it was so much easier, because it gave me the gift of certainty. It is not really the extra hour and a bit which would've been stressful; it was the uncertainty which would've been stress-inducing. If you told me ahead of time "your RfA will last 169 hours and 7 minutes", I would be fine (even if I had questioned why we were being that specific). People have been through a week of heck; there to add additional uncertainty because of 'crat (un)availability.
Superlative questions
As a very minor point, I would love a ban on superlative questions ("best", "worst", etc.). Please don't ask them; they are almost impossible to answer. Things like standard question 2 (best contributions) are okay, but something like Q15 ("To turn the last couple of questions around, what change, possibly controversial in its time, has been the most beneficial to Wikipedia in the long term?") would have been much easier to answer if it was to "turn the last couple of questions around, what is one change, possibly controversial in its time, that has been beneficial to Wikipedia in the long term?" I haven't studied all changes to Wikipedia, so I could not and cannot answer that question. I essentially pivoted in my answer to the "what is one change" question. Don't make candidates answer impossible questions :)
But what about standard Q2 (about your best contributions)? I can answer about what I have done personally. And nobody is going to oppose you because they think your most valuable contributions were not mentioned in Q2, but they might very well oppose you because you consider a typo a bigger deal than deleting the Main Page. So superlatives are fine if they are positive ("best" etc.) and about the candidates actions, but at that point you are just re-asking Q2. So don't ask superlative questions!
And a thank you to everyone who participated
Thank you—sincerely—to everyone who participated in the discussion. Whether you supported, opposed, remained in the neutral section, asked a question, or left a comment; thank you. You took the time to investigate and vet a random internet stranger, and I am appreciative and grateful for your time. Thank you to those who supported and put their trust in me, and thank you to those who opposed for keeping it civil and leaving me with things to work on.
Notes
Ball games, movies, elections, but nothing really weird
- This traffic report is adapted from the Top 25 Report, prepared with commentary.
Let's play ball, shootin' down the walls, yeah (June 23 to 29)
I know, I know for sure, that life is beautiful around the world (June 30 to July 6)
I'm afraid of Americans (July 7 to 13)
I'm afraid of the world (July 14 to 20)
I'm afraid I can't help them (July 21 to 27)
Exclusions
- These lists exclude the Wikipedia main page, non-article pages (such as redlinks), and anomalous entries (such as DDoS attacks or likely automated views). Since mobile view data became available to the Report in October 2014, we exclude articles that have almost no mobile views (5–6% or less) or almost all mobile views (94–95% or more) because they are very likely to be automated views based on our experience and research of the issue. Please feel free to discuss any removal on the Top 25 Report talk page if you wish.
I'm proud to be a template

Good afternoon. Hello there! I'm a template... an English Wikipedia template, yes.
Are you sure it's me you're after, friend?
Ah, I suppose it's just as well — it's just been years since anybody came out to see me. Well, then, what would you like? You need a string formatted? Sure thing. I've got just the code to do it. You want the input string cut in half? No problem. Let me just—ah. Tarnation! My back...
No, it's okay. I'm all well. I just can't parse like I used to. Just give me a moment and I'll... what's that, friend? A backslash? Ohh, now that's a tough one. I have to say I can't recall how those are supposed to... hmm... no, listen here, I said I'm fine. Just give me a minute, will you? You can sit down over there if you please. Would you like a cup of tea?
You know, you might not believe it, but I used to be one of the most used templates on this whole site. I was protected. Heck – I was cascade-protected. Now, back in those days, the way they did that was that one admin had a subpage of a subpage of a userpage and... ah, never mind. It doesn't matter anymore. The point is, well, there are six or seven million articles now, ye? There were just a million in those days, and about half of those had some kind of template on them that would call on yours truly. And I'd chop off the namespace names, or the root page names – this was before {{ROOTPAGENAMEE}}, mind you – didn't matter to me, it was all honest work.
Sometimes you'd get some codface vandal who would use me to spell out curse words. The old Scunthorpe bit. Now of course I didn't like that, but when you're a template you parse the input and you return the output, it was all the same to me. Now, this was in the very old days, of course. We didn't have anything else! It was just me out there with my own arms and legs. We didn't have steam engines or gasoline, it was just me and maybe a plow horse if I was lucky. The templates these days don't even know what it was like. But I won't complain, back in those days you could just chop up your strings and get three square meals out of it, and a pension to boot. I feel bad for the whippersnappers out there. My son's a template too — I taught him everything I know — and he's got a real natural knack for splitting strings too. But from what he tells me it's a plum different game out there now. You've got no guarantees nowadays. You've got to pay attention to all this stuff — test cases, sandboxes, expensive parser functions — back in my day we just put in a day's work and were done with it!
.jpeg)
In fact, that reminds me – if you really want to get a great heap of strings split up, you should go see my son. Why, he can split seven hundred strings in the time it takes me to split one. They wrote him with that newfangled scripting language. I'm so proud of him! I'll finish this one for you, and you can go see him instead – my arms are already getting tired.
Well, thank you for stopping by anyway, friend. I do live a comfortable life now, so it's not often I get a chance to get back in the old boots. At the very least, you got your strings split, and I've got something to tell my son about tomorrow when he comes to visit. Now I could use another cup of tea — would you like one as well? If you're going to be traveling it's good to have something to keep you warm.
I tell you what: it's not easy when you get to be seventeen years old.